深入了解浏览器利用(一)
By dwj1210 at
这是一个关于浏览器漏洞利用的系列文章。我们将从编译 WebKit 和 JavaScriptCore 开始,然后了解一些内部结构以及如何调试,由浅入深学习浏览器漏洞利用的技巧。文章原文:https://liveoverflow.com/topic/browser-exploitation/ 本文对原文进行了翻译、校正、踩坑并添加了自己的理解。
构建 WebKit
WebKit 是一种 Web 浏览器引擎,用于许多产品,例如 macOS 和 iOS 上的 Safari、Nintendo、Switch 和 PlayStation。我们可以将 WebKit 主要分解为两个不同的组件:
- WebCore:负责 HTML 布局、渲染和 DOM 的库。
- JavaScriptCore:提供 JavaScript 引擎的库。
现在我们需要构建一个环境来进行测试,所以首先可以通过 github 来下载 Webkit 源代码,但是目前版本已将上述漏洞修复。并且 github 中的 WebKit 仓库中已经搜索不到 commit hash 为 3af5ce129e6636350a887d01237a65c2fce77823 历史版本代码,估计是被删除了。大家可以从 这里 下载源代码。
在 macOS 上构建 WebKit,我们需要安装 Xcode,并且正确配置。
# Install
$ xcode-select --install
already installed...
# Make sure xcode path is properly set
$ xcode-select -p
/Applications/Xcode.app/Contents/Developer
# Confirm installation
$ xcodebuild -version
Xcode 14.1
Build version 14B47b然后执行构建 debug 版本 JSC 的脚本
# Run the script which builds the WebKit
Tools/Scripts/build-webkit --jsc-only --debug
# jsc-only : JavaScriptCore only
# debug : With debug symbols在构建中你可能会遇到一些错误。
- 错误
Source/WTF/wtf/RAMSize.cpp:36:10: fatal error: 'sys/sysinfo.h' file not found这个是由于当前版本未兼容 macOS 平台编译,从 github 上最新版本的 https://github.com/WebKit/WebKit/blob/main/Source/WTF/wtf/RAMSize.cpp 文件中复制代码替换 RAMSize.cpp 即可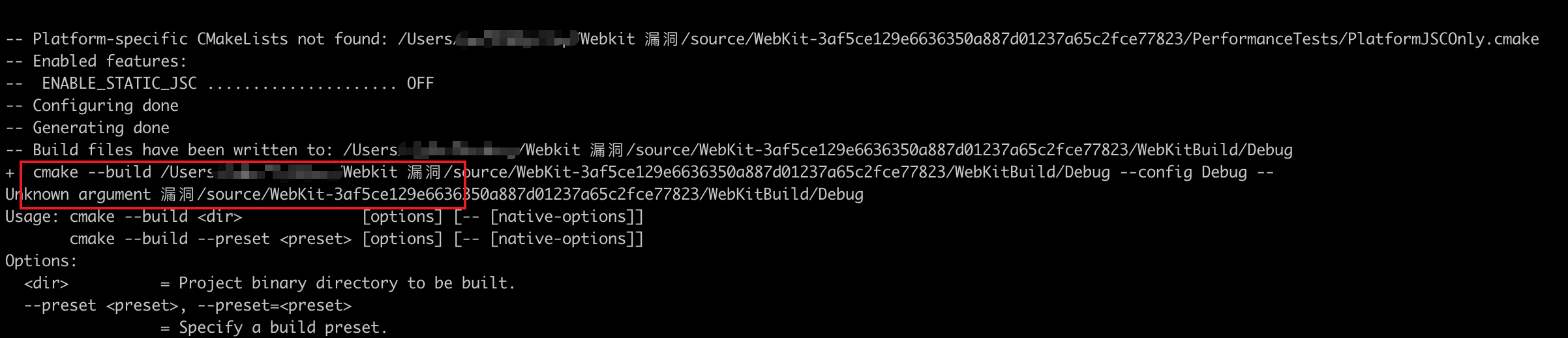
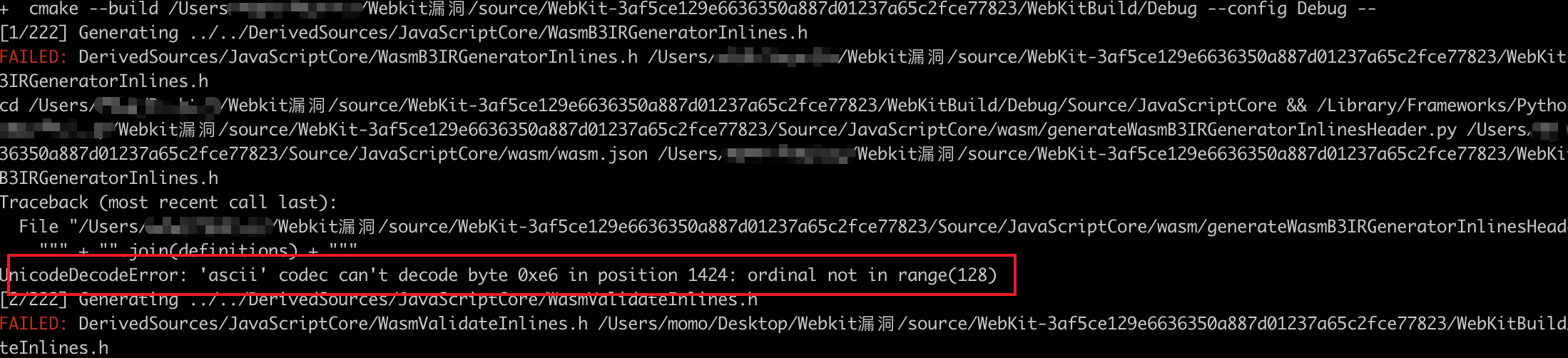
- 错误
Source/JavaScriptCore/tools/JSDollarVM.cpp:180:37: error: reference to 'Handle' is ambiguous,在 JSDollarVM.cpp 文件的 180 行,修改Handle为JSC::Handle即可
- 或者你的路径中存在中文
JavaScriptCore 运行时
在构建完成后,我们可以在 ./WebKitBuild/Debug/bin/jsc 路径中找到二进制文件,执行二进制文件,会进入一个交互式的编程环境(Read Eval Print Loop),它类似一个 NodeJs 或者浏览器的 JS console。
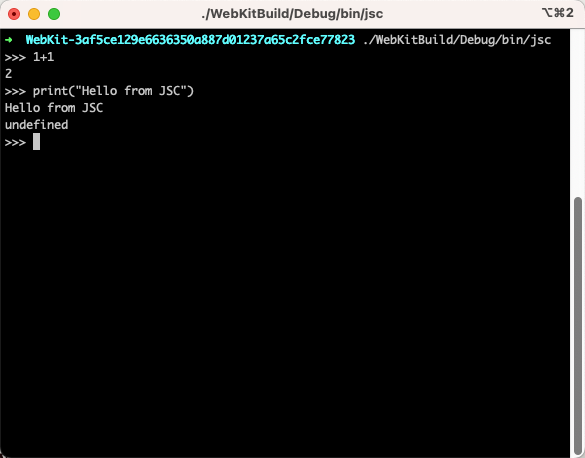
JS 中有一个函数 describe() 可以帮助理解任何对象
>>> describe(1)
Int32: 1这里 Int32 代表 32 位整数类型,值是 1
>>> describe(13.37)
Double: 4623716258932001341, 13.370000这里 4623716258932001341 是双精度的原始值在内存中的表示方式,我们可以使用 python 的 struct 模块将其轻松解码为 13.37
>>> # This is Python Interpreter
>>> import struct
>>> # We pack the value with `Q` which means `unsigned long long`(64 bit Integer) and
>>> struct.pack("q", 4623716258932001341)
b'=\n\xd7\xa3p\xbd*@'
>>> # then we unpack these raw bytes with `d`(double), hence we get back the value.
>>> struct.unpack("d", struct.pack("q", 4623716258932001341))
(13.37,)关于 struct 库中数据格式转换的对照表可以参考:https://docs.python.org/2/library/struct.html#struct-format-strings
回到 jsc 解释器,当尝试描述一个字符串时,我们考试看到更多的信息
>>> describe("string")
String (atomic) (identifier): string, StructureID: 4显然,字符串有一个叫做 StructureID 的属性,这个我们稍后会继续了解,现在再使用 describe() 函数来描述一个数组
>>> describe([1, 2, 3])
Object: 0x1508c02b0 with butterfly 0x15300c010 (Structure 0x15083abc0:[Array, {}, CopyOnWriteArrayWithInt32, Proto:0x1508900a0, Leaf]), StructureID: 101所以这个数组的是一个位于内存地址 0x1508c02b0 的对象,并且有一个名为 butterfly 的属性。底层数据结构为 CopyOnWriteArrayWithInt32,通过这个我们可以看出来这应该是一个整数数值组成的数组,现在让我们添加一个浮点数来更改该数组的值。
>>> describe([1, 2, 3.456])
Object: 0x1508c02c0 with butterfly 0x15300c040 (Structure 0x15083ac30:[Array, {}, CopyOnWriteArrayWithDouble, Proto:0x1508900a0, Leaf]), StructureID: 102我们可以看到,此时数组更改为 CopyOnWriteArrayWithDouble,这意味着整数也被转换成为 Double 类型。现在我们向数组中列表中尝试添加一个字符串
>>> describe([1, 2, 3.456, "78"])
Object: 0x1508c02d0 with butterfly 0x15300c070 (Structure 0x15083aca0:[Array, {}, CopyOnWriteArrayWithContiguous, Proto:0x1508900a0, Leaf]), StructureID: 103现在这个数组变得更加通用,因为它保存了不同类型的值。如果我们继续尝试,比如往数组中添加一个数组,会看到数组类型再次发生了变化
>>> describe([{}, 1, 13.37, [1, 2, 3], "test"])
Object: 0x1508c02f0 with butterfly 0x150968008 (Structure 0x15083aa70:[Array, {}, ArrayWithContiguous, Proto:0x1508900a0]), StructureID: 98现在数组类型变成了 ArrayWithContiguous,它不再是 "CopyOnWrite" 数组了。我们看到的这些变化,这将对于理解 WebKit 对象内部结构信息将会非常有用。
LLDB 调试
lldb 是一个类似于 gdb 的调试器,我们可以使用 lldb 来调试 jsc。
# Load the file to the debugger
$ lldb ./WebKitBuild/Debug/bin/jsc
(lldb) target create "./WebKitBuild/Debug/bin/jsc"
Current executable set to '/Users/momo/Desktop/Webkit/source/WebKit-3af5ce129e6636350a887d01237a65c2fce77823/WebKitBuild/Debug/bin/jsc' (arm64).
(lldb) run
Process 15929 launched: '/Users/momo/Desktop/Webkit/source/WebKit-3af5ce129e6636350a887d01237a65c2fce77823/WebKitBuild/Debug/bin/jsc' (arm64)回到 JSC
现在我们已经将调试器附加到了 jsc 解释器,我们创建一个数组并进行更深入的研究
>>> a = [1, 2, 3, 4]
1,2,3,4
>>> describe(a)
Object: 0x1010c02b0 with butterfly 0x10282c008 (Structure 0x10103a990:[Array, {}, ArrayWithInt32, Proto:0x1010900a0, Leaf]), StructureID: 96对象地址位于 0x1010c02b0 ,butterfly 位于 0x10282c008,让我们按 Ctrl+C 来离开 JavaScript 解释器,并进入 lldb。
(lldb) x/8gx 0x1010c02b0
0x1010c02b0: 0x0108210500000060 0x000000010282c008
0x1010c02c0: 0x00000000badbeef0 0x00000000badbeef0
0x1010c02d0: 0x00000000badbeef0 0x00000000badbeef0
0x1010c02e0: 0x00000000badbeef0 0x00000000badbeef0在这里,第二个值 0x000000010282c008 就是 butterfly 的地址,让我们看下 butterfly 的内存
(lldb) x/8gx 0x000000010282c008
0x10282c008: 0xffff000000000001 0xffff000000000002
0x10282c018: 0xffff000000000003 0xffff000000000004
0x10282c028: 0x0000000000000000 0x00000000badbeef0
0x10282c038: 0x00000000badbeef0 0x00000000badbeef0仔细观察,我们可以找到一些看起来像数组值的数字 [1, 2, 3, 4]
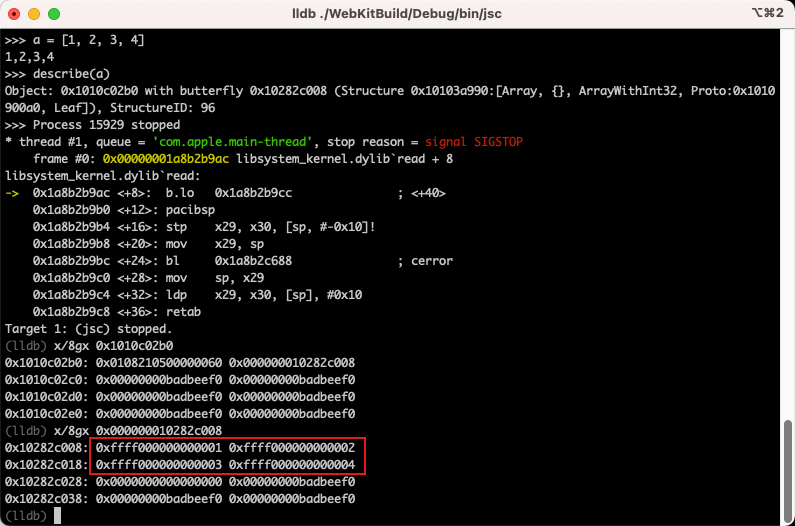
但是奇怪的是,这些值的高位字节被设置为 ffff,我们稍后将会理解这是为什么。
The Sources for JSValue
JSValue 类是 JavaScript 中一个非常重要的类,用于处理大量中值,我们可以在 JSCJSValue.h(位于 Source/JavaScriptCore/runtime/JSCJSValue.h) 中找到类的定义,从中我们还可以看到它似乎能够处理许多不同的类型,例如整数、双精度数或者布尔值。
//[...]
bool isInt32() const;
bool isUInt32() const;
bool isDouble() const;
bool isTrue() const;
bool isFalse() const;
int32_t asInt32() const;
uint32_t asUInt32() const;
std::optional<uint32_t> tryGetAsUint32Index();
std::optional<int32_t> tryGetAsInt32();
int64_t asAnyInt() const;
uint32_t asUInt32AsAnyInt() const;
int32_t asInt32AsAnyInt() const;
double asDouble() const;
bool asBoolean() const;
double asNumber() const;
//[...]在这个头文件中还包含一大段注释,解释什么是 JSValue。
//[...]
#elif USE(JSVALUE64)
/*
* On 64-bit platforms USE(JSVALUE64) should be defined, and we use a NaN-encoded
* form for immediates.
*
* The encoding makes use of unused NaN space in the IEEE754 representation. Any value
* with the top 13 bits set represents a QNaN (with the sign bit set). QNaN values
* can encode a 51-bit payload. Hardware produced and C-library payloads typically
* have a payload of zero. We assume that non-zero payloads are available to encode
* pointer and integer values. Since any 64-bit bit pattern where the top 15 bits are
* all set represents a NaN with a non-zero payload, we can use this space in the NaN
* ranges to encode other values (however there are also other ranges of NaN space that
* could have been selected).
*
* This range of NaN space is represented by 64-bit numbers begining with the 16-bit
* hex patterns 0xFFFE and 0xFFFF - we rely on the fact that no valid double-precision
* numbers will fall in these ranges.
*
* The top 16-bits denote the type of the encoded JSValue:
*
* Pointer { 0000:PPPP:PPPP:PPPP
* / 0001:****:****:****
* Double { ...
* \ FFFE:****:****:****
* Integer { FFFF:0000:IIII:IIII
* *
* The scheme we have implemented encodes double precision values by performing a
* 64-bit integer addition of the value 2^48 to the number. After this manipulation
* no encoded double-precision value will begin with the pattern 0x0000 or 0xFFFF.
* Values must be decoded by reversing this operation before subsequent floating point
* operations may be peformed.
*
* 32-bit signed integers are marked with the 16-bit tag 0xFFFF.
*
* The tag 0x0000 denotes a pointer, or another form of tagged immediate. Boolean,
* null and undefined values are represented by specific, invalid pointer values:
*
* False: 0x06
* True: 0x07
* Undefined: 0x0a
* Null: 0x02
*
* These values have the following properties:
* - Bit 1 (TagBitTypeOther) is set for all four values, allowing real pointers to be
* quickly distinguished from all immediate values, including these invalid pointers.
* - With bit 3 is masked out (TagBitUndefined) Undefined and Null share the
* same value, allowing null & undefined to be quickly detected.
*
* No valid JSValue will have the bit pattern 0x0, this is used to represent array
* holes, and as a C++ 'no value' result (e.g. JSValue() has an internal value of 0).
*/仔细阅读这段注释,可以看到 “JSValue 的编码表”,这解释了为什么在数组中看到了 0xffff。JSValue 可以包含不同的类型,高位用来定义它是什么,这也解释了为什么 JavaScript 尽管运行在 64 位设备上,但只处理 32 位整数,因为 JSValue 通过将最高 32 位 设置为 0xffff0000 来对整数进行编码。如果高位时 0x0000,则它是个指针,0x0000 到 0xffff 中间的任何内容都是浮点数/双精度数。
总结一下就是:
- Pointer: [0000][xxxx:xxxx:xxxx](前两个字节为0,后六个字节寻址)
- Double: [0001~FFFE][xxxx:xxxx:xxxx]
- Intger: [FFFF][0000:xxxx:xxxx](只有低四个字节表示数字)
- False: [0000:0000:0000:0006]
- True: [0000:0000:0000:0007]
- Undefined: [0000:0000:0000:000a]
- Null:[0000:0000:0000:0002]
此时让我们看看内存中的情况。
使用调试器
作为第一个测试,我们可以创建一个包含各种不同类型的奇怪数组,然后在内存中查看它。我们或许可以发现一个奇怪的现象,因为第一个元素应该是整数。然而,当查看内存时,发现它是一个浮点数,这是怎么回事 ?
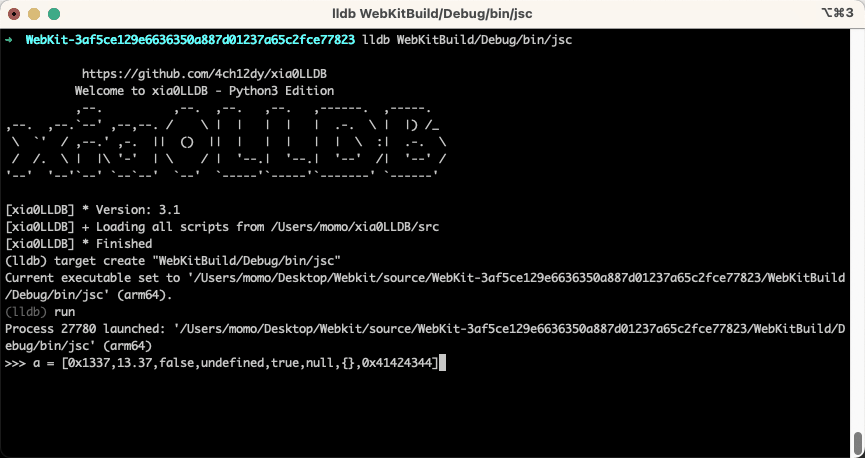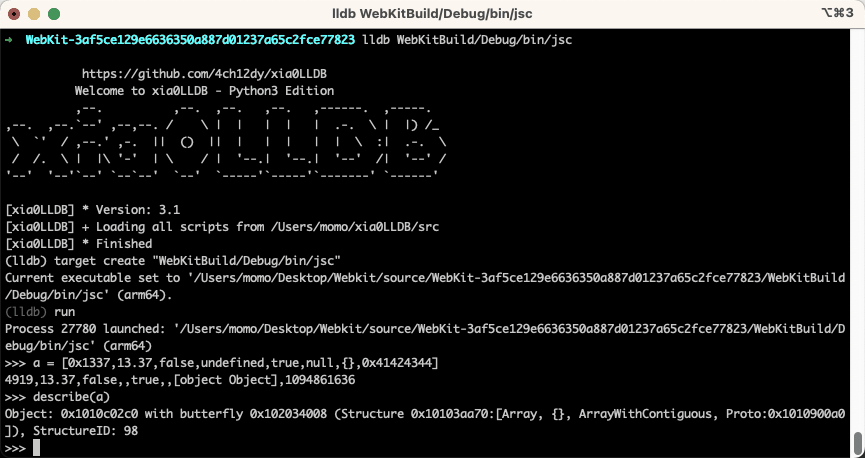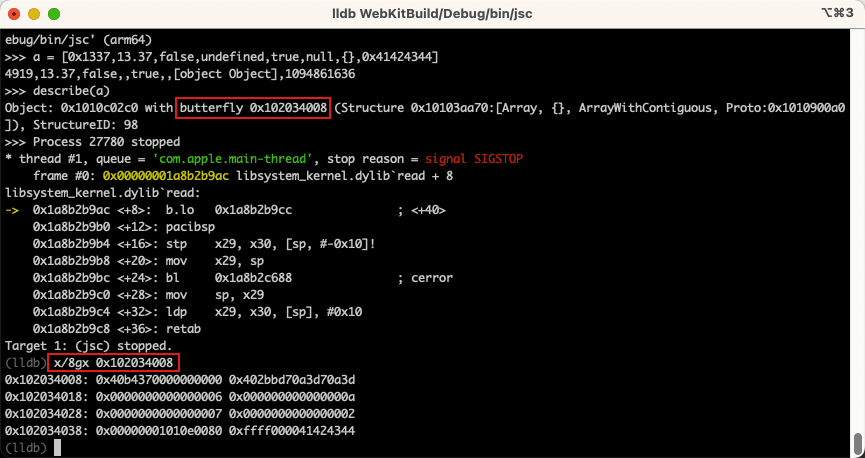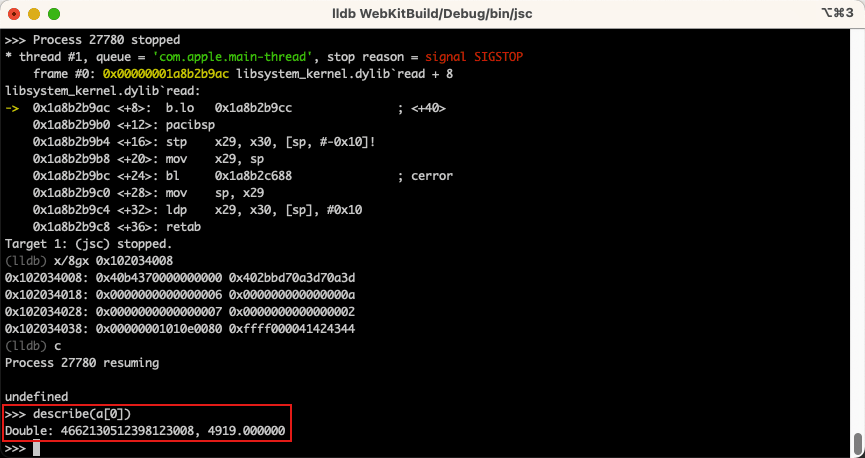
此时让我们慢慢地逐个元素的构建数组。通过这样做,我们可以观察到整个数组的内部类型不断变化,并且第一个元素有时也会转换为浮点数。

识别内存中的 JSValue
此时让我们回到上面构建的“一个包含各种不同类型的奇怪数组”,并再次查看它的 butterfly

这个时候我们通过将内存中数组的值于 JSValue 的信息进行比较,我们可以轻松识别出 undefined 或者 false 等常量。以及 0x0000 开头的指针、0xffff 开头的整型。

这里是我们创建的空 javascript 对象显示为指针,所以这是一个地址,而实际的对象储存在 0x1010e0080。
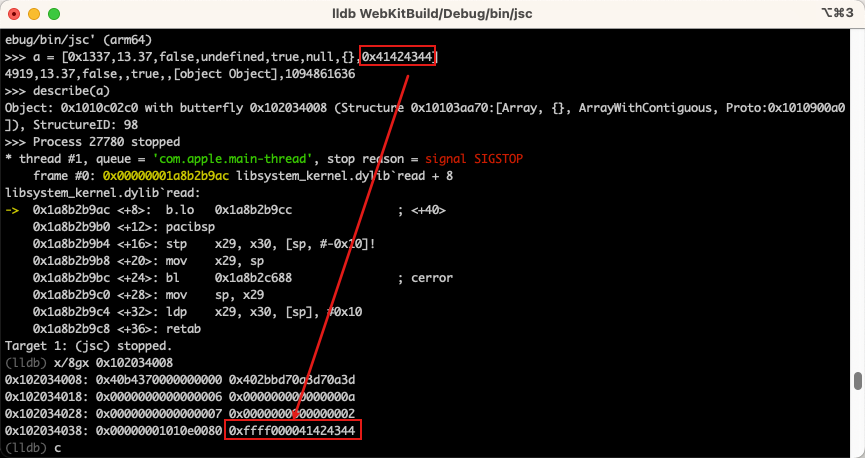
这里是以 0xffff 开头为前缀的整数。
The Butterfly
当使用 describe() 函数查看对象时,我们看到了一个 butterfly 的地址。通过研究内存,我们已经知道它包含数组的元素,但是为什么叫做蝴蝶呢?
当我们查看这个地址指向的位置时就就明白了。通过地址/指针指向结构的开头,但 butterfly 它指向中间。指针的右侧是数组元素,指针的左侧是数组长度和其他对象属性的值。
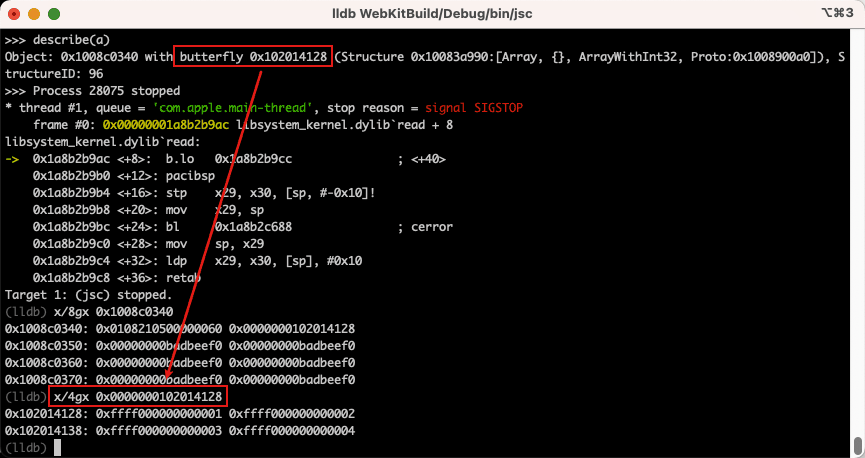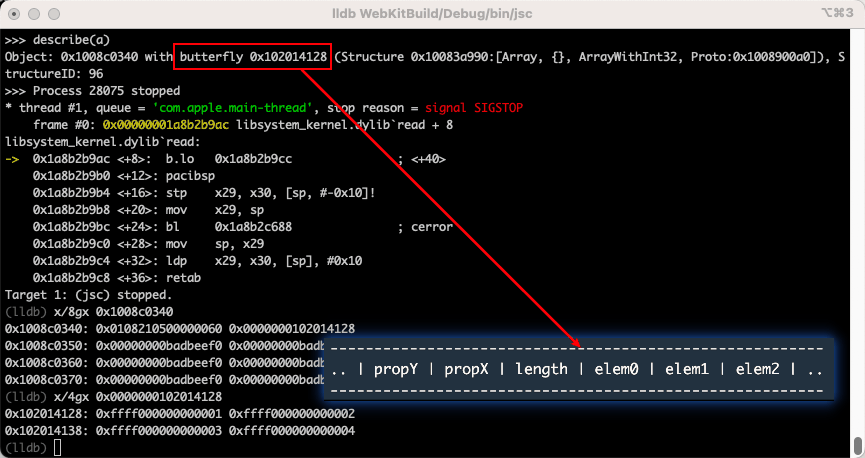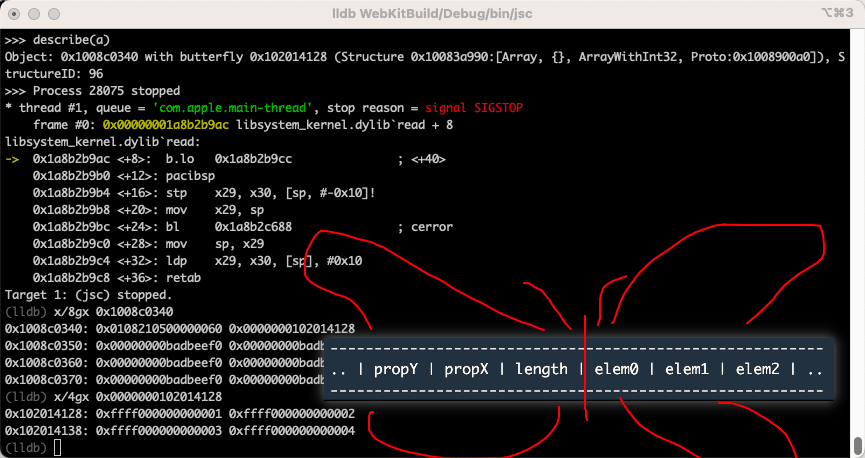
实际上使用 butterfly 储存数据时一个可选项,如果对象属性不多(不大于 6 个)而且不是数组时,对象的属性将不会申请 butterfly,而是储存在对象内部,内存结构如下:
object : objectHeader butterfly(Null)
object+0x10 : prop_1 prop_2
object+0x20 : prop_3 prop_4
object+0x30 : prop_5 prop_6The Structure ID
除了 butterfly,我们还在内存中看到了一些属于该对象的其他值。前 8 个字节包含描述一些内部属性的标志及非常重要的 StructureID,该数字定义了特定偏移量的结构。
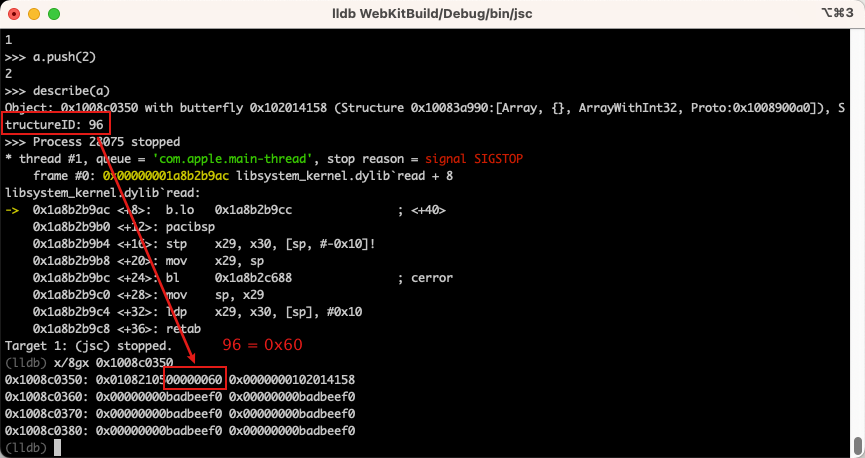
此时我们尝试对数组进行修改,给数组 a = [1, 2] 添加属性: a.x = 3, x.y = 4
此时再次使用 describe() 函数查看对象,发现对象的 butterfly、StructureID 等都发生了变化。

当我们给对象添加新属性时,我们会发现 StructureID 发生了变化。StructureID 关系到了 JavaScript 引擎如何去访问对象的属性,因为访问属性在JavaScript中是一个十分频繁的操作,为了提高访问速度,每个主流的JavaScript引擎都对此做了优化。
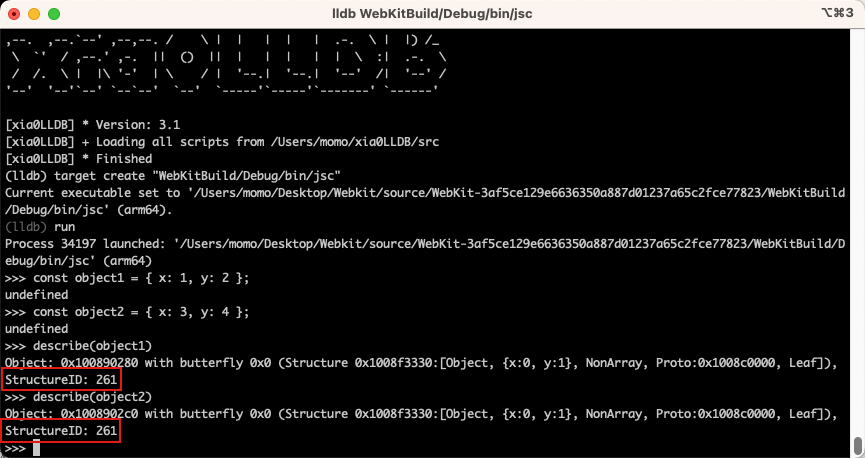
作为对象键值的字符串,如果储存在对象的内存中将会十分浪费空间,因为这样的话每生成一个对象就多出一份键值的拷贝。而在 JavaScript 中,多个对象具有相同的属性是经常发生的事情,从某个方面来讲,这些对象都具有相同的形状(Shapes),也可以说巨头相同的结构(Structure)。比如:
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };object1 和 object2 虽然是两个不同的对象,但是他们的键值都是一样的。这种情况下它们就具有相同的结构,在JavaScriptCore 中也能看到它们具有相同的 StructureID。
如果我们要访问对象的属性,JSC 就会先根据 StructureID 找到对应的 Structure,然后找到对应的属性名,读取属性在内联存储或者是 butterfly 中的偏移值,最后读取属性值。
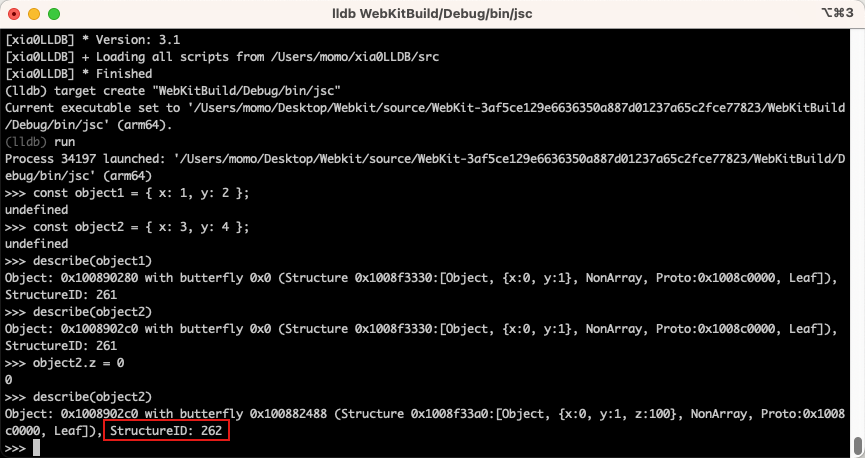
当通过给对象的属性赋值或者添加新属性时,我们可以看到 StructureID 何时改变或不改变。例如,当向像这样的对象添加属性时object1.z = 0,我们注意到 StructureID 发生了变化。实际上,如果还不存在具有这种结构的对象,则会创建一个新的 StructureID,并且我们还可以看到它只是简单地递增。
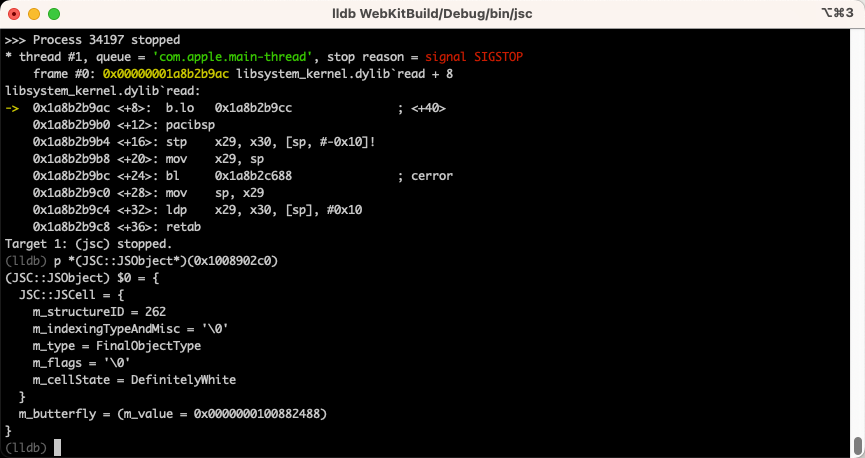
当然我们也可以使用 lldb 来打印对象 debug 版本的符号信息,比如下图中显示的 StructureID 和其他内部属性属于 JSCell 头,并且 butterfly 是属于 JSObject 类的一部分。
最后
在这篇文章中我们探讨了 JavaScriptCore(WebKit 中的 JavaScript 引擎)如何在内存中存储对象和值。接下来在后面的文章中将继续学习 JIT、addrof(),fakeobj() 等内容,让我们离漏洞更近一步。
参考
https://liveoverflow.com/topic/browser-exploitation/ https://www.anquanke.com/post/id/183804